A Kubernetes cluster is a set of virtual or physical machines on network nodes. They are the architecture’s worker machines. To understand the cost of this shared environment, first use the features in Kubernetes to create a cost structure that mirrors your organization’s needs.
A Kubernetes cluster is a set of virtual or physical machines on network nodes. They are the architecture’s worker machines. To understand the cost of this shared environment, first use the features in Kubernetes to create a cost structure that mirrors your organization’s needs.
You can track costs at the cluster level when using Amazon’s Elastic Kubernetes Service (EKS), but this can be expensive. Kubernetes provides several additional ways to create a cost infrastructure. At a lower level, you can track namespaces, pods, deployments, labels, and tags.
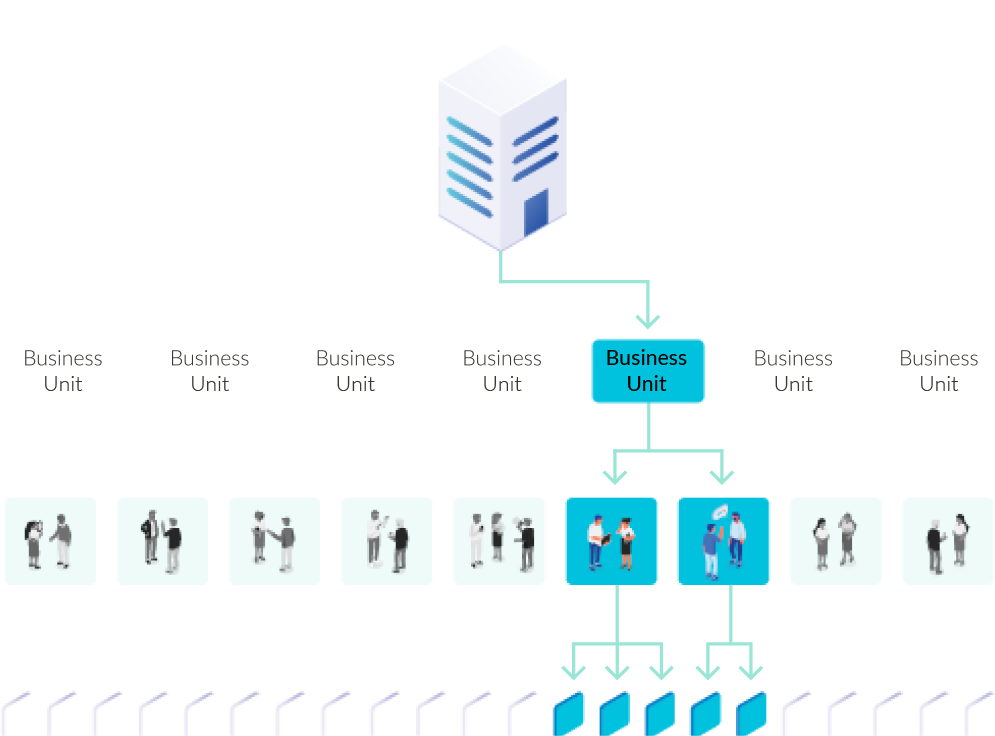
A namespace enables you to create multiple virtual clusters within the same physical cluster. This enables users on different teams to access the same physical environment. While you could place each team into different clusters, this may be more costly in volume pricing. A namespace enables you to balance the need for separation with economies of scale.
A pod is a set of containers running on your cluster. A pod is the smallest unit of workload processing that you can deploy to a node. A pod’s containers may be related to each other or not. A Kubernetes deployment creates or modifies pod instances. Deployments scale the number of replica pods, update code, or roll back earlier deployments.
Labels are key-value pairs attached to objects within Kubernetes. They specify attributes that are meaningful to users. Labels help you understand the structure or use of objects from a user’s point of view, and they enable you to select and operate on a Kubernetes object. They map parts of the system to an organization’s structure or group or aggregate the parts by level.
Tags provide an even lower level of granularity. These are user-defined key-value pairs for multiple technical and business needs, such as cost allocation, technical tracking, and security.
While Kubernetes provides resource tracking through these objects, it is up to the organization to structure, tune, and monitor them to create a helpful allocation system.

Cost analysis and control are essential financial functions, but a typical cloud deployment is like a black box to the finance department. While finance can run monthly reports to get the deployment cost, they don’t know what causes these trends. IT Operations must tie the individual cloud deployment instances to separate groups or users for finance to get helpful information.
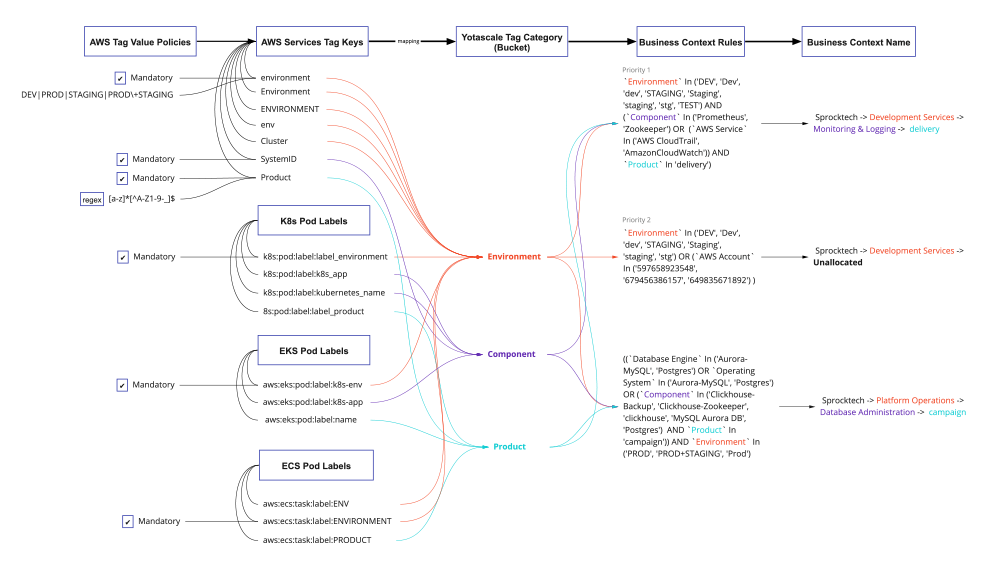
While namespaces, pods, and deployments provide some granularity, they often don’t mirror the organization’s functional cost structure. Further complicating the matter is that subdivisions like namespace, pods, deployments, and labels primarily assist information technology operations. So, the business has only a limited ability to manipulate these designations for cost allocation. Tags offer the flexibility an organization needs to structure information so it can control spending.
Tags are metadata attached to resources or groups of resources. For example, you can add tags to a virtual machine (VM) to designate its function (development, test, or production). You can also attach an additional tag to the same VM to assign it to project or organization relationships. This flexibility enables you to create the structure you need to mirror your organizational needs. Costs are then associated with these tags, driving various analytics to understand and control these costs.
Organizations often make the mistake of allowing each department or team to implement their own tagging processes. Standardize and automate tag structures across the organization to get the most significant benefit from their analytics.
This process starts with developing naming standards for tags. Remember that tags can be anything that helps understand resource allocation within a business unit, the team, the application using it, or its function.
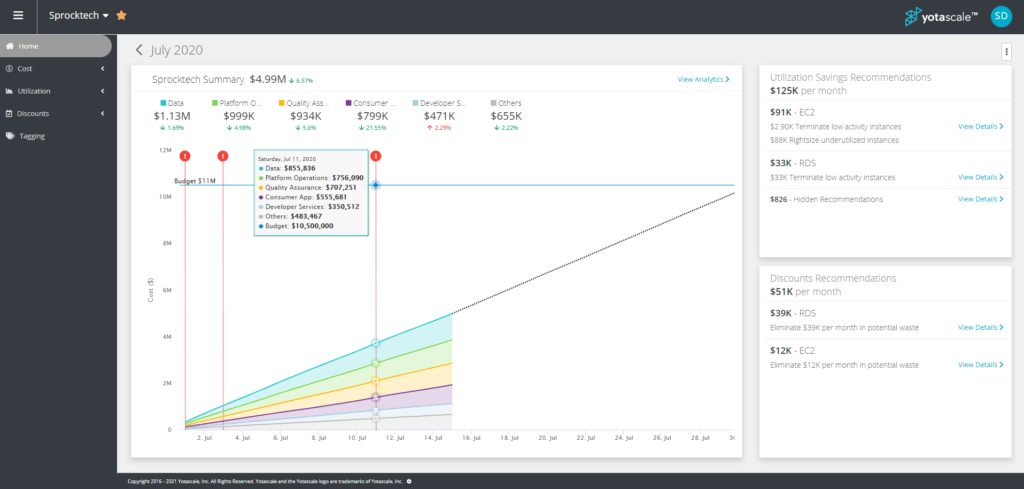
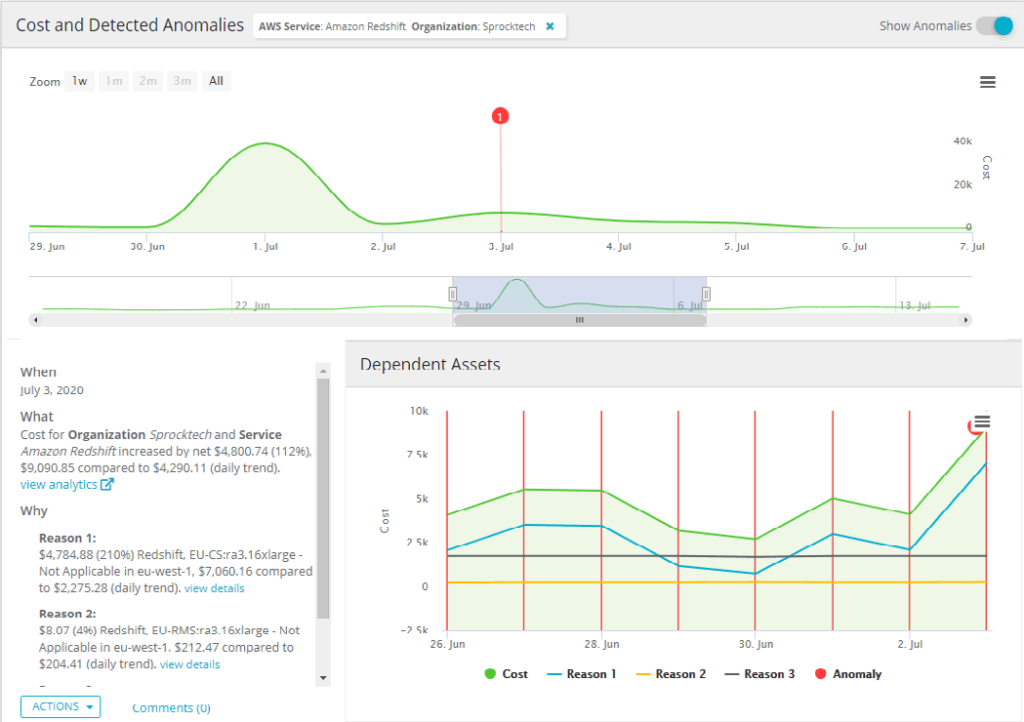
 Yotascale analyzes these statistics and makes cost and utilization recommendations based on that analysis. In this case, Yotascale recommended terminating underused Amazon Elastic Compute Cloud (EC2) and Relational Database Service (RDS) resources. It also recommended curtailing resource reservations to be consistent with their use. Users can drill down either by organizations or by recommendations to get a clear picture of use or why Yotascale made its recommendations. All the expected features, such as changing timeframe or organization views, are available.
Yotascale analyzes these statistics and makes cost and utilization recommendations based on that analysis. In this case, Yotascale recommended terminating underused Amazon Elastic Compute Cloud (EC2) and Relational Database Service (RDS) resources. It also recommended curtailing resource reservations to be consistent with their use. Users can drill down either by organizations or by recommendations to get a clear picture of use or why Yotascale made its recommendations. All the expected features, such as changing timeframe or organization views, are available.
Allocating costs for multi-tenant containers can be challenging. Yotascale handles this cost allocation challenge by showing key values within a cluster using namespaces or containers to fairly distribute both use and reservation costs. This feature is essential in customer chargebacks.
Together, the ability to granularly decompose multi-tenant cluster costs and Yotascale’s Contexts feature provide fine-grained, per-team usage costs. Combine the Contexts view with prices for traditional cloud infrastructures, like software instances, databases, and a network, for a complete picture of each team’s infrastructure expenses. Assigning costs back to teams provides both the information and motivation for them to control their Kubernetes costs.
Kubernetes enables various teams to have independent operations. Rather than requesting resources and waiting for approval by a central information technology decision-maker, with Kubernetes’ ability to scale up or down, organizations can be nimble and productive.
An unfortunate by-product of this independence is many people adding to the cost of AWS resources. Also, because of the large number of players, it’s challenging to predict how costs will compare to the budget at the end of any period.
Actions by many individuals introduce variability, making it more challenging to decide on simple predictive methods. Yotascale’s budgeting and forecasting functions use machine learning to send near real-time alerts on potential budget overages to the individuals responsible. These alerts enable individuals to focus on potential problem areas and adjust their use rather than getting an ugly surprise at the end of the month.